
System administration tools used by Big Data platforms manage distributed data across multiple nodes. This enables automatic data redundancy, server failover and higher rates of access to data. (Source: Petrolink)
Over the last few years businesses in virtually every industry have developed data-led strategies to solve their challenges. From Amazon to Netflix, American Express and a host of other major corporations, Big Data is used to inform decisions and improve both success and revenue.
For the oil and gas industry, dealing with Big Data isn’t new. Now, with an ever-increasing amount of data being collected by thousands of sensors with surface facilities monitoring it in real time, the ability to successfully leverage vast amounts of data has been heightened to a new level.
The problem
The problem with Big Data isn’t so much the volume but the diversity of the data.
While the industry has a great appetite for Big Data, it is not always easy to digest. Big Data is only useful if companies are able to extract insights from it. Multiple inputs in real time make it challenging to collect, interpret and leverage the disparate data. When working with a client in North America, Petrolink found that its challenge is the discrepancy between the data it has available from its surface sensors and service providers contrasted with what its engineering systems need to effectively manage its operations.
Right time, right person
Big Data technologies integrate common and disparate datasets to deliver the right information at the appropriate time to the correct decision- maker. The new infrastructures for Big Data are faster, more robust and always on. They offer distributed processing where the data come to the person as opposed to bringing the person to the data. But there is room for improvement.
Improving the ‘five Vs’ of Big Data
Big Data is defined by five key characteristics:
- Volume: the amount of data;
- Veracity: making sure the data are accurate;
- Velocity: the speed in which data are accessible;
- Variety: the various types of data; and
- Variability: the consistency of the data.
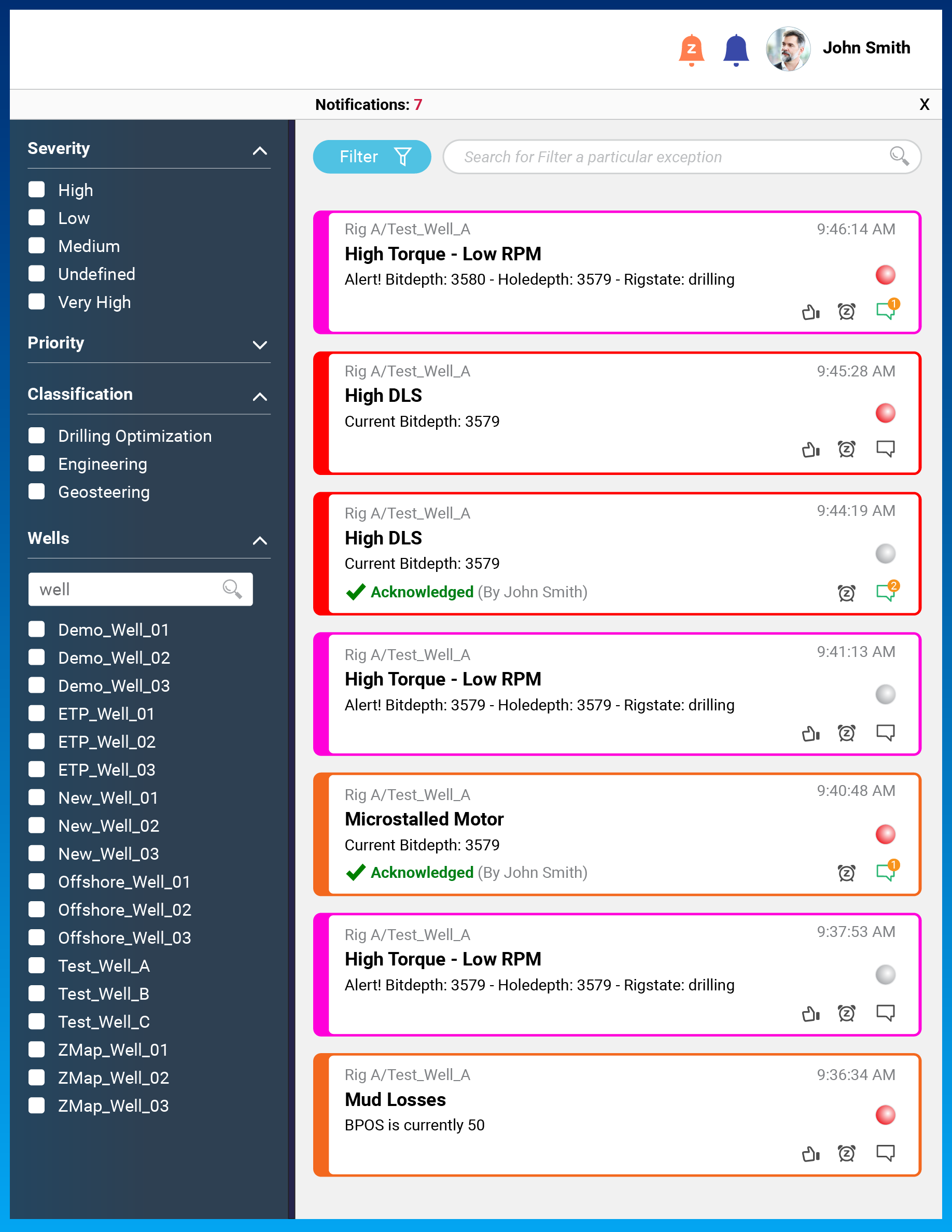
All of these pose problems. But in each of these areas new and valuable improvements have been made. One is Petrolink’s manage by exception (MBE) processes. This collection of tools attacks the problem by first allowing the analytical access to data where engineers or specialists can augment the real-time data through customized algorithms. These algorithms can be designed such that they will address one or many questions, allowing the system to enhance the user’s ability to understand the current situation. The second of these analytical tools is an advanced alerting system that has the flexibility to monitor and evaluate numerous types of data streams, including the abovementioned derived values.
One U.S.-based supermajor has indicated that the use of managing operations by exception is key to reducing drilling risk and improving efficiency. By using Big Data and rule-driven alarms, the company expects intelligent alarms to reduce nonproductive time (NPT) by a few percent but at the same time also reduce risks by assisting the engineering team with awareness of critical concerns. As soon as data arrive at the point of aggregation, MBE conducts condition monitoring of rig operations and drillstring sensor data. No matter where the company or service team is located, the MBE system immediately sends mission-critical alerting information to the rig, real-time operations center and back office. All that is required is an internet-capable computer and permission to access the system.
Any user may create an alerting rule and share it with the rest of the team. A user can designate which wells and wellbores are monitored and acknowledge the corresponding alerts to everyone on the MBE system. It is designed to permit users to select the alerts they wish to receive and acknowledge as part of their job responsibilities, thus reducing alert overload. If an alert remains unacknowledged for a specific period of time, the MBE system may automatically escalate it to a specified group of users for action.
Why Big Data is essential
The analytic algorithms are complex, and the datasets are large; however, there is an additional complication. The data are also unpredictable because they’re based on the geology and on monitoring that happens thousands of feet away. Calculations that are slowed down due to users having to wait for the data will impede the realtime process. With their advanced processing speeds, Big Data infrastructures are designed to solve that problem.
Users accessing the system require the flexibility to run models and simulations in real time looking for similarities against the actual data. The results of these simulations help the team members who are involved in the drilling activities to have confidence in their understanding of the interaction between the subsurface geology and the mechanical drilling process.
To accomplish these two opposing needs (variability and flexibility), Big Data infrastructures must rely on standardization of data, parallel processing to accommodate the number of scenarios and users and distributed computation to enable analysis to be done at the point data are acquired.
An example of this type of analysis is the ongoing process of identifying NPT and reducing it as a function of balancing operational efficiency and drilling safety. A part of this requires prediction and prevention of unwanted events by projecting ahead of the current bit location and anticipating what will occur in the next few feet or hours.
Drillers can now make decisions in real time instead of near real time. The challenge with traditional systems is that drillers do post-analysis using historic data and then plan the next drilling interval, whereas a Big Data system delivers models that are continuously updating. Drillers can then make decisions in real time that positively impact the current interval being drilled.
Taking steps to know the unknown
Understanding common problems such as stuck pipe or loss of circulation can help companies avoid huge amounts of unnecessary costs. Studies have estimated global industry losses related to stuck pipe and lost circulation to be in the order of $2 billion per year. This is more than twice the total amount spent to buy drillpipe in the first place and represents nearly 20% of the total recorded NPT losses associated with drilling.
“Data standards are a prerequisite step toward Big Data analytics and process automation,” said Ross Philo, Energistics president and CEO. “Energistics data standards have been developed in collaboration with the industry to allow operators to have a higher level of confidence in the decisions being made and deliver measurable and repeatable savings to the industry.”
To take predictive analytics and alerts to the next level, Petrolink’s Big Data system uses the previously mentioned MBE processes. By using the real-time data and the standards that the Big Data solutions incorporate, the company is able to provide dynamic alerts for real-time conditions based on deviations from the model.
Creating a better predictive platform
The industry is undergoing a revolution, one where realtime data are part of every aspect in the decision-making process. To reach this new level, the industry needs to rethink data collection, data standardization, cost of transfer and acquisition, and easy access to this information. Providing these capabilities at speed anywhere decisions are made is the basis for tomorrow’s predictive platform based on Big Data.
Recommended Reading

Wayangankar: Golden Era for US Natural Gas Storage – Version 2.0
2024-04-19 - While the current resurgence in gas storage is reminiscent of the 2000s —an era that saw ~400 Bcf of storage capacity additions — the market drivers providing the tailwinds today are drastically different from that cycle.
Ozark Gas Transmission’s Pipeline Supply Access Project in Service
2024-04-18 - Black Bear Transmission’s subsidiary Ozark Gas Transmission placed its supply access project in service on April 8, providing increased gas supply reliability for Ozark shippers.

Kinder Morgan Sees Need for Another Permian NatGas Pipeline
2024-04-18 - Negative prices, tight capacity and upcoming demand are driving natural gas leaders at Kinder Morgan to think about more takeaway capacity.
Scathing Court Ruling Hits Energy Transfer’s Louisiana Legal Disputes
2024-04-17 - A recent Energy Transfer filing with FERC may signal a change in strategy, an analyst says.
Balticconnector Gas Pipeline Will be in Commercial Use Again April 22, Gasgrid Says
2024-04-17 - The Balticconnector subsea gas link between Estonia and Finland was damaged in October along with three telecoms cables.