
(Source: Hart Energy; Shutterstock.com)
[Editor's note: A version of this story appears in the May 2020 edition of E&P. Subscribe to the magazine here.]
For all its operational innovation and wildcatter reputation, the oil and gas industry lags other sectors when it comes to cloud adoption. Of the $60 billion spent annually on cloud services, only 5% of that comes from the upstream energy business.
Necessity has stepped up the pace of adoption, however. In the belt-tightening years since the 2014 oil price collapse, energy companies have focused on harnessing the power of the cloud and artificial intelligence to shorten the time to discovery and optimize asset productivity.
Wrestling with petabytes of seismic data
The subsurface industry has experienced a longstanding challenge to efficiently access secure, reliable, seismic and well data on a global scale.

Historically, oil and gas companies consume most of the world’s high-performance computing (HPC) for processing seismic data to deliver an image of the subsurface. Still, the demand for HPC peaks only a few times a year. Cloud solutions can give these organizations the ability to scale up and down based purely on demand, so they can pay only for what they need and use. Organizations without a digital solution for their subsurface data must purchase the necessary disk space for the high volume of seismic data they use only occasionally. Most of the disk space that is not used becomes obsolete. On the other hand, cloud solutions can ramp up or ramp down data storage at a moment’s notice.
For major oil and gas companies, the question is no longer whether to use contemporary cloud technology, it’s how to overcome inherent limitations in existing seismic data formats and streamline cloud implementation.
Outdated file formats
One of the most common seismic storage media types, the SEG-Y file format, was created in 1975 for tape storage. Like a cassette tape that forces listeners to fast-forward through all the songs before getting to the one they want to hear, these trace-based file systems are stored sequentially. When organizations need to access the old versions of the data for reprocessing or to double-check an interpretation, the tape must be mounted on a computer and read so the end user can access it. Of course, reading is a costly and time-consuming process that can lead to data loss.
Most applications that work with SEG-Y data were developed 20 years ago. To overcome the limits of SEG-Y, internal formats were created to load the data from SEG-Y, creating a paradigm that requires SEG-Y data to be copied to the local applications. Sequential storage makes those formats very inefficient in a cloud setting, where data is expected to be stored in an “object” format, unlike files on a PC.
It’s no surprise that companies are reluctant to move petabytes of seismic data to the cloud. But a data technology that overcomes the inherent limitations in existing seismic data formats might be what it takes to change their minds.
Empowering geoscientists
To unlock the efficiencies that modern-day computing provides, Bluware began developing Volume Data Store (VDS) two decades ago. With VDS, visualization of large pre-stack seismic data sets and cost-effective cloud storage can now be achieved without disrupting legacy application workflows.
VDS is a cloud-native object format. Compression is built into the system, so when a project starts, the user can easily stream data at the appropriate compression level to and from the cloud, saving time and costs.
Bluware Flexible Access Storage Transcoding converts seismic data in VDS format and streams it to a user’s interpretation application. It does so by acting as a translator between VDS and the read requests made by the application in the format the legacy application uses. This is a significant benefit for data management processes as it enables a single source of data in a central location, as opposed to having to copy and convert data multiple times for specific applications to run.
As an example of the efficiency and accuracy gains of cloud computing and machine learning, a recent study used Bluware’s VDS data format and interactive deep learning technology to assist interpreters in tedious tasks involving seismic fault and chimney interpretation workflows.
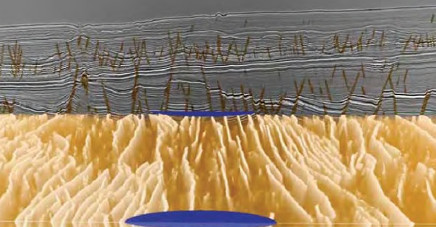
Usually, an interpreter spends weeks or months to interpret a survey and its volume fully. In this case, the interpreter labeled the data (blue faults) and observed the deep learning inference (green faults) in real time until the results were desirable (Figure 1).
Bluware’s interactive deep learning technology eliminates data preparation by leveraging the capabilities of VDS. The time spent on data preparation was instantly reduced to zero. The desired results were achieved after performing training on 2% of the in-lines within the volume, accelerating interpretation by 20 times when compared to traditional manual seismic interpretation (Figure 2). Geoscientists did not have to post-process the results because they were able to conduct quality control during the labeling and training process.
Bluware is contributing VDS technology to the subsurface industry’s collaborative effort to create an open, standards-based data ecosystem.
Solving an industry problem
In Spring 2018, a group of leading oil and gas companies formed the Open Subsurface Data Universe (OSDU) Forum called The Open Group. Their goal was to enable new and existing cloud-native data-driven applications with seamless access to subsurface and wells data.
According to the OSDU website, the consortium’s core principle is to separate lifecycle data management from the applications enabling innovation. They say this will be achieved by developing a common data platform with standard public application programming interfaces (APIs) and involving global cloud hosting vendors to build working implementations.
In addition, the OSDU Forum’s ambitions include enabling standardized access to subsurface data—a mission Bluware felt its open version of VDS, called OpenVDS, aligned with.
OpenVDS is a set of tools and an open-source API to read and write data in VDS format. OpenVDS does not compress data, but it can read compressed data. When compared to other seismic data formats, OpenVDS offers powerful capabilities such as random access to data that is cloud-native, which is a significant step forward for the industry. In fact, it has been accepted as a format for seismic data by OSDU.
Preparing for the future
In an era of Big Data analytics, the power of the cloud brings managing and interpreting enormous volumes of seismic data down to size. Migrating seismic data to the cloud does not have to be daunting, though open source and commercial applications can make the right move an easy one.
Recommended Reading

Kimmeridge Fast Forwards on SilverBow with Takeover Bid
2024-03-13 - Investment firm Kimmeridge Energy Management, which first asked for additional SilverBow Resources board seats, has followed up with a buyout offer. A deal would make a nearly 1 Bcfe/d Eagle Ford pureplay.

Laredo Oil Subsidiary, Erehwon Enter Into Drilling Agreement with Texakoma
2024-03-14 - The agreement with Lustre Oil and Erehwon Oil & Gas would allow Texakoma to participate in the development of 7,375 net acres of mineral rights in Valley County, Montana.

SLB’s ChampionX Acquisition Key to Production Recovery Market
2024-04-21 - During a quarterly earnings call, SLB CEO Olivier Le Peuch highlighted the production recovery market as a key part of the company’s growth strategy.

From Restructuring to Reinvention, Weatherford Upbeat on Upcycle
2024-02-11 - Weatherford CEO Girish Saligram charts course for growth as the company looks to enter the third year of what appears to be a long upcycle.

JMR Services, A-Plus P&A to Merge Companies
2024-03-05 - The combined organization will operate under JMR Services and aims to become the largest pure-play plug and abandonment company in the nation.